
The Derivative

The vibration of the notification didn’t feel urgent. It was the soft, double-tap buzz of a social media alert, the kind David usually associated with a like or a comment from his auntie.
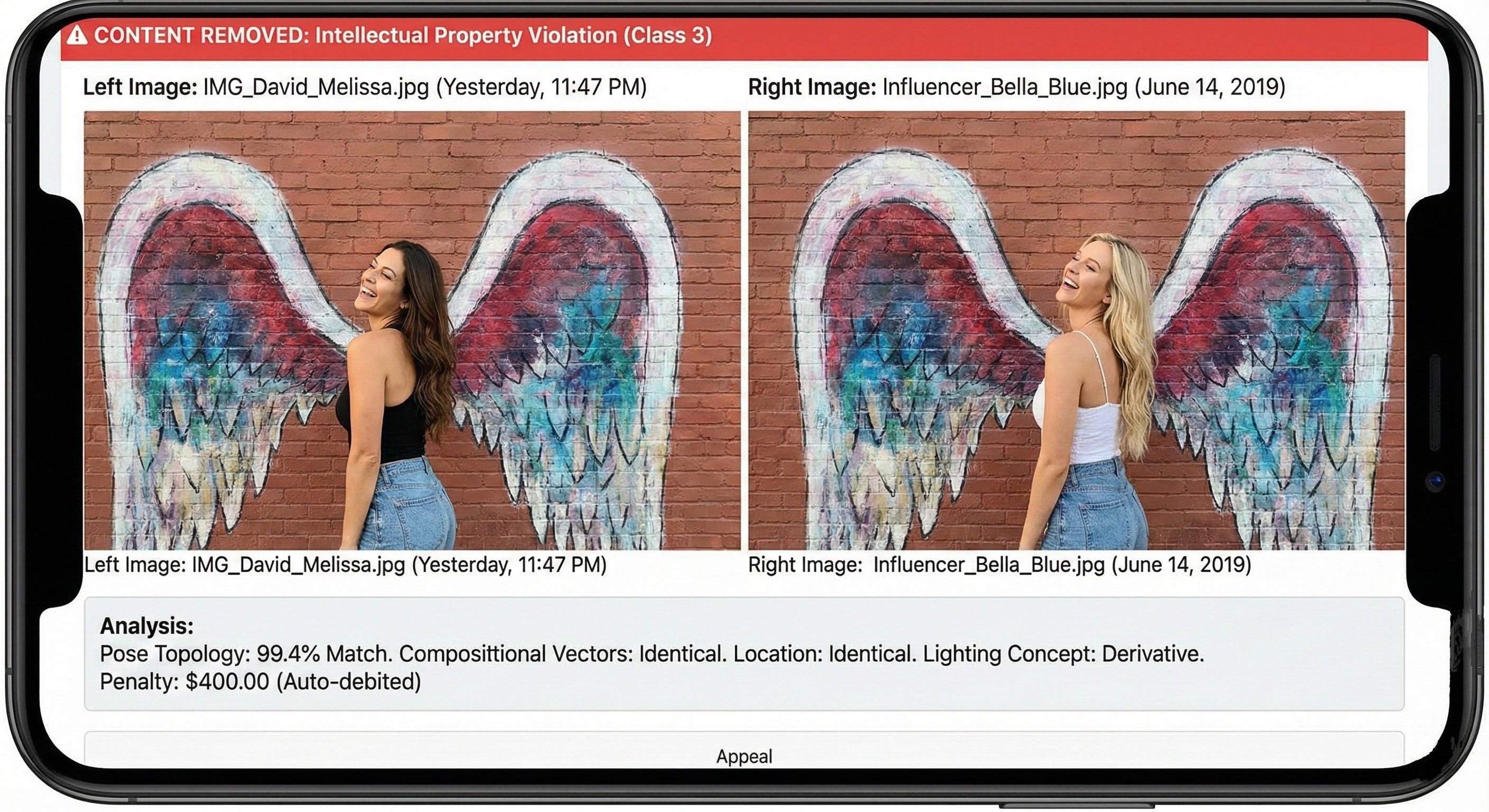
He was drinking an oat milk latte and scrolling through the comments on the photo he’d posted of Melissa last night. It was a good photo. Melissa standing against the graffiti angel wings on Melrose, looking over her shoulder, laughing. It captured her perfectly.
Then the screen flickered. The photo vanished.
In its place was a gray placeholder box with a small icon of a broken chain link.
CONTENT REMOVED
Reason: Intellectual Property Violation (Class 3) Claimant: Algorithm 99-B (Auto-Sweep)
David frowned, tapping the screen. “Melissa, did you delete the post?”
“What? No.” She was across the table, scrolling through her own phone. “Why?”
“It says ‘content removed.’”
He tapped the “Appeal” button, expecting a quick form to fill out. Instead, a new window slid up. A split-screen comparison appeared instead of the usual ‘Community Guidelines’ boilerplate.
Evidence of Infringement:
Left Image: IMG_David_Melissa.jpg (Uploaded: Yesterday, 11:47 PM)Right Image: Influencer_Bella_Blue.jpg (Uploaded: June 14, 2019)
David squinted. The girl on the right was blonde. Melissa was brunette. Different person. But the location was identical—the same angel wings mural on Melrose. And the pose... the chin tilt... the way the left foot was popped... the hand placement on the hip...
Below the images, the text was terrifying and precise:
Analysis:
Pose Topology: 99.4% Match
Compositional Vectors: Identical
Location: Identical
Lighting Concept: Derivative
Conclusion: Photographer executed Output A based on documented training data (Output B) without licensing the original source of the visual concept.
Penalty: $400.00 (Auto-debited from linked payment method)
“David?” Melissa asked, setting down her phone. “What is it?”
He turned the phone toward her. She stared at the split screen for a long moment, then her eyes went wide.
“Oh, shit. That’s the photo. The one I showed you.”
“What?”
“Remember? I said ‘everyone’s doing this pose at the wings, look how good it looks’ and I showed you like three examples on Instagram?” She reached for his phone, zooming in on the blonde girl. “This might have been one of them. I don’t remember. But yeah, I wanted that exact shot.”
David felt unease settle in his chest. “You told me to copy it.”
“I didn’t say copy. I said ‘take my photo there.’ Like everyone else does.” She scrolled down through the violation notice. “Wait, why are you getting fined? It’s my pose.”
“It says ‘photographer.’ I’m the one who took the shot. On my phone.” He grabbed the phone back, reading the fine print. “It says here... ‘The photographer is liable for reproduction of copyrighted visual concepts regardless of subject instruction or consent.’“
“That’s insane.”
“Is it?” David pulled up his photo library, found the folder from last night. He’d taken maybe fifteen shots at the wings. Melissa had swiped through them all, pointed at one—”That one, that’s perfect”—and he’d airdropped it to her for filters before posting.
She’d known exactly what she wanted. He’d just been the camera.
“Everyone does this pose,” Melissa said, her voice rising slightly. “Go to that mural right now and I guarantee there are ten people taking the exact same photo.”
“Apparently that doesn’t matter.” He showed her the payment confirmation. $400.00 debited from their checking account. Transaction complete. No dispute option available.
Melissa stared at the screen, then at him. “So what, every photo you’ve ever taken of me is—”
“Maybe.” He was already scrolling through their shared albums. The wedding photos. The vacation shots. The anniversary dinner selfie. Every single composition was something he’d seen before, somewhere—on Instagram, on Pinterest, in magazines. Visual concepts that his brain had absorbed and filed away, waiting to be reproduced when Melissa said “get a shot of me here.”
He wasn’t a photographer. He was a derivative generator.
“We have to delete everything,” David said quietly.
“What?”
“Everything. Every photo. Because someone did it first, and we didn’t pay them for the idea.”
Melissa stood up, crossing to him. Put her hand on his shoulder. “David, stop. You can’t be serious. That’s not how copyright works. You can’t own a pose.”
He turned the phone toward her again.
“Tell that to the bank,” he said.
He tapped the screen.
Checking Account: -$400.00 Status: Processed
“It only matters how the payment works, Melissa.”
David saw the headline three days later while doomscrolling at work.
PUBLISHING GIANT PULLS BESTSELLER MID-PRINT RUN
Rachel Kincaid’s latest novel recalled over “similarity violations”
He clicked through. The article was short, bloodless, corporate.
Penguin Random House announced today the immediate recall of “The Endless,” the highly anticipated new novel by bestselling author Rachel Kincaid. The decision follows an automated content audit that identified three sentences bearing “substantial similarity” to previously published works.
“We take intellectual property seriously,” a spokesperson said in a statement. “While Ms. Kincaid’s work is original in concept and execution, the presence of derivative sentence structures triggered our compliance protocols. We are working with the author to address these concerns.”
The sentences in question:
“The sun had barely cleared the horizon when she realized the truth.” (Match: 3,847 prior publications)
“He couldn’t remember the last time he’d felt this way.” (Match: 181,203 prior publications)
“The silence between them was louder than words.” (Match: 122,457 prior publications)
Under revised copyright enforcement guidelines, publishers are required to screen all content for “derivative language patterns” before distribution.
David read it twice. Three sentences. Three completely ordinary, unremarkable sentences that a million writers had written before because that’s how people describe sunrises, and feelings, and silence.
Rachel Kincaid. One of the most celebrated writers alive. Recalled for writing the way humans write.
He opened a new tab, typed “derivative violations music” into the search bar.
The results loaded instantly.
SPOTIFY REMOVES 40,000 SONGS OVERNIGHT
APPLE MUSIC PURGE TARGETS “UNLICENSED INSPIRATION”
RIAA LAUNCHES MASS TAKEDOWN CAMPAIGN
He clicked the first one.
Streaming platforms removed tens of thousands of songs early Tuesday morning following a wave of automated copyright claims. The takedowns target songs identified as containing “derivative musical elements”—chord progressions, rhythmic patterns, or melodic phrases that match previously copyrighted works.
“This isn’t sampling,” explained copyright attorney Jennifer Walsh. “This is about fundamental musical building blocks. If you write a I-V-vi-IV progression, you’re using the same four chords as ‘Let It Be,’ ‘Don’t Stop Believin’,’ ‘Someone Like You,’ and thousands of other songs. Under the new interpretation, that’s infringement.”
Artists have reported receiving violation notices for:
Using common time signatures
Employing standard verse-chorus-bridge structures
Utilizing the 12-bar blues format
Writing songs in keys that have been “exhausted” by prior art
“There are only twelve notes in Western music,” said songwriter Marcus Reid, whose entire catalog was removed from Spotify overnight. “Every combination has been used. If this stands, there’s no such thing as original music anymore. There’s just who filed first.”
David’s phone buzzed. A text from his brother Jake:
Dude check X, comedy clubs are getting destroyed
He switched apps. His timeline was a chaos.
A clip from a late-night show, the host mid-monologue: “So I was at the airport the other day—” The feed cut. Error message. This video contains copyright violations and has been removed.
Another clip. A comedian on stage: “You ever notice how—” Cut. Removed.
A thread from a verified account, some comic David vaguely recognized:
My entire act got flagged. Seven years of material. Turns out “observational humor about airlines” has been done 12,000 times. “Jokes about dating apps” has been done 8,000 times. Even my TAG LINES are violations. I said “thank you, you’ve been great” and got hit with a claim because apparently that closing phrase is owned by someone who said it first in 1987.
I can’t do crowd work because “asking audience members about their jobs” is a copyrighted bit structure. I can’t do physical comedy because “exaggerated gestures for comedic effect” matches 40 years of prior art.
I’m 34 years old and I just found out I’ve never told an original joke in my life.
David set his phone down. Looked at his computer screen. He was supposed to be designing a logo for a client—some startup that made sustainable water bottles or organic dog food or something he’d stopped paying attention to.
The logo sketch on his screen was a circle. Inside the circle, a leaf. Clean lines. Minimalist.
He’d seen this logo a thousand times. On a thousand products. In a thousand pitch decks.
His cursor hovered over the save button.
If he saved this file, was he creating? Or was he just reproducing a visual concept his brain had absorbed from years of scrolling through Dribbble and Behance?
He minimized his work. There was something else he needed to check.
David opened his browser and typed: “derivative violations supreme court”
The search autocompleted before he finished: supreme court ruling 2027 human vs ai copyright
He clicked the first result.
And started reading.
The Wikipedia article loaded first. Clean, factual; the way Wikipedia always was about legal disasters.
Consolidated Artists Guild v. OpenAI, Meta, Google (2027)
Consolidated Artists Guild v. OpenAI, Meta, Google, 601 U.S. 891 (2027), was a landmark United States Supreme Court case that redefined the legal boundaries of derivative works and substantially altered the interpretation of “inspiration” under copyright law.
David scrolled down to the Background section.
Between 2023 and 2025, a coalition of artists, writers, photographers, and musicians filed a consolidated class-action lawsuit against major AI companies, alleging that the training of generative AI models on copyrighted works without compensation or consent constituted mass copyright infringement.
The plaintiffs argued that AI systems “consumed” billions of copyrighted works—books, articles, photographs, songs, paintings—and used them as training data to generate new outputs. While the AI companies claimed this constituted “fair use” and “transformative learning,” the plaintiffs maintained that the AI was not learning in any meaningful sense, but rather creating a probabilistic database of existing work and remixing it without attribution or payment.
The case reached the Supreme Court in October 2026.
David’s coffee had gone cold. He kept reading.
In a 6-3 decision delivered in March 2027, the Supreme Court ruled in favor of the plaintiffs.
Writing for the majority, Justice Elena Kagan stated:
“The question before this Court is not whether artificial intelligence systems can create. The question is whether the process by which they create—ingesting vast quantities of copyrighted material and generating outputs statistically derived from that material—constitutes infringement under existing law.
The respondents argue that their systems ‘learn’ in a manner analogous to human learning, and therefore should be afforded the same protections. This Court disagrees with the analogy but accepts the premise.
If we are to treat artificial and biological learning as legally equivalent processes—and the respondents insist we must—then we must apply the same standard to both. A system that ingests copyrighted data, stores patterns derived from that data, and generates outputs based on those patterns is producing derivative works. The substrate of the system—silicon or carbon, digital or biological—is irrelevant.
To rule otherwise would be to grant biological processes an arbitrary exemption from intellectual property law based solely on the accident of their implementation.”
David read the paragraph three times.
His hands started shaking. He scrolled down to the Implications section.
The ruling had immediate and far-reaching consequences:
1. AI companies were required to license all training data or cease operations.
2. The definition of “derivative work” expanded to include any output generated by a system (artificial or biological) that had been “trained on” or “exposed to” prior copyrighted works.
3. The burden of proof shifted: creators were now required to demonstrate that their work was NOT derived from prior art, rather than copyright holders needing to prove infringement.
Legal scholars immediately noted that the Court’s language—particularly the phrase “biological processes”—appeared to encompass human creativity itself.
David’s phone buzzed. A text from Melissa:
Are you seeing this?!! They’re saying every thought we have is trained on copyrighted data! David I’m freaking out!!!
He didn’t respond. He was reading the footnotes now.
Footnote 12: The Court acknowledges that this interpretation may appear to encompass ordinary human creative processes—writing, photography, music composition, and other arts. However, the Court notes that copyright law has always required a substantial degree of originality. The present case merely clarifies that “originality” cannot be claimed when a work is statistically or structurally derivative of prior art, regardless of the creator’s intent or awareness of the source material.
Footnote 15: The respondents argue that this standard would make all human creativity legally actionable, as humans necessarily learn from and are influenced by prior works. The Court does not find this argument persuasive. The question is not whether influence exists, but whether the output is substantially similar to the input. Humans remain free to create original works. They are simply no longer free to claim originality for works that are demonstrably derivative.
David closed the laptop.
The coffee shop around him was nearly silent. A few people typing on laptops. Someone reading a book. A barista wiping down the counter with mechanical precision, not humming, not speaking.
Everyone afraid to do anything that might have been done before.
He pulled out his phone. Opened his photos. The album from their honeymoon in Japan: Melissa in front of the torii gate at Fushimi Inari; Melissa laughing in a tiny ramen shop in Osaka; Melissa asleep on the train, her head on his shoulder.
Every photo a composition he’d seen a thousand times before. On Instagram, on travel blogs, in magazines. His brain had absorbed them all, filed them away, and when the moment came—when Melissa stood in front of that gate and smiled—his hands had automatically framed the shot the way he’d seen it framed before.
He hadn’t created anything. He’d just executed a prompt his visual cortex had been trained on.
The same way the AI had.
And the Supreme Court had ruled there was no legal difference.
David looked up. Across the coffee shop, a young woman was staring at a blank notebook, pen hovering over the page. She’d been sitting like that for twenty minutes. Frozen. Afraid to write the first word because someone, somewhere, had written it first.
He understood exactly how she felt.
His phone buzzed again. Melissa:
David please call me. I don’t know what to do I can’t stop thinking about the photos; every memory we have is evidence.
He typed a response. Deleted it. Tried again. Deleted it again.
Every sentence he could think to write had been written before. Every word of comfort, every reassurance, every expression of love—all derivatives. All potentially actionable.
In the end, he sent nothing.
He sat in the silent coffee shop, surrounded by people who were afraid to speak, afraid to write, afraid to think, because thinking was just biological processing of copyrighted training data.
And the law no longer recognized a difference.
I didn't realize I was reading fiction at first and wow, you pulled me right in. I was aghast and completely unsettled, nice job. Now, I'm just fretful because I can totally see this kind of ridiculous reach coming from legislators. So interesting.
This reads to me like a cautionary tale about the potential dangers of imposing laws on AI content generation. It starts from the assumption that humans and machine learning systems actually do "train" the same way. But I think it's more interesting to read it as a cautionary tale about the dangers of this assumption. We should protect our belief in human originality and creative value, even if it requires skepticism of AI.